SAGE Publishing
SAGE is a leading international provider of innovative, high-quality content, publishing more than 1000 journals and over 800 new books each year, spanning a wide range of subject areas in business, humanities, social sciences, science, technology and medicine. SAGE’s growing selection of library products includes archives, data, case studies and video.
Business challenge
SAGE wanted to improve the quality of engagement between the sales team and their institutional customers in order to best serve their customers. As part of this, the sales team worked to create tailored value reports containing detailed information about how SAGE products fit each institution’s information needs. This involved examining the course curricula and research profiles of each institution and analysing them against SAGE content. It was a very manual and time-consuming process involving a series of searches amongst all the different products. The reports were very useful in helping the sales team suggest suitable materials to current and potential clients during sales visits, but there needed to be a better way of creating them.
SAGE had already undertaken a major strategic exercise to create and apply a taxonomy of around 61,000 unique terms across their product base of around 2.5 million content items. It powers SAGE Recommends, their discovery tool that suggests semantic recommendations for further reading. SAGE wanted to leverage their investment by extending its use to other applications supporting the business.
They therefore decided to prioritise a web-based tool to help the sales team create the tailored value reports.
The solution
SAGE asked 67 Bricks to undertake an R&D project to create a working prototype tool that would take a description of an educational course and return a list of SAGE content relevant to the course. SAGE chose 67 Bricks because they needed a partner who could help them creatively and collaboratively with defining and prioritising the requirements, and who had solid experience on the semantic side. They were also keen to try out an agile project methodology.
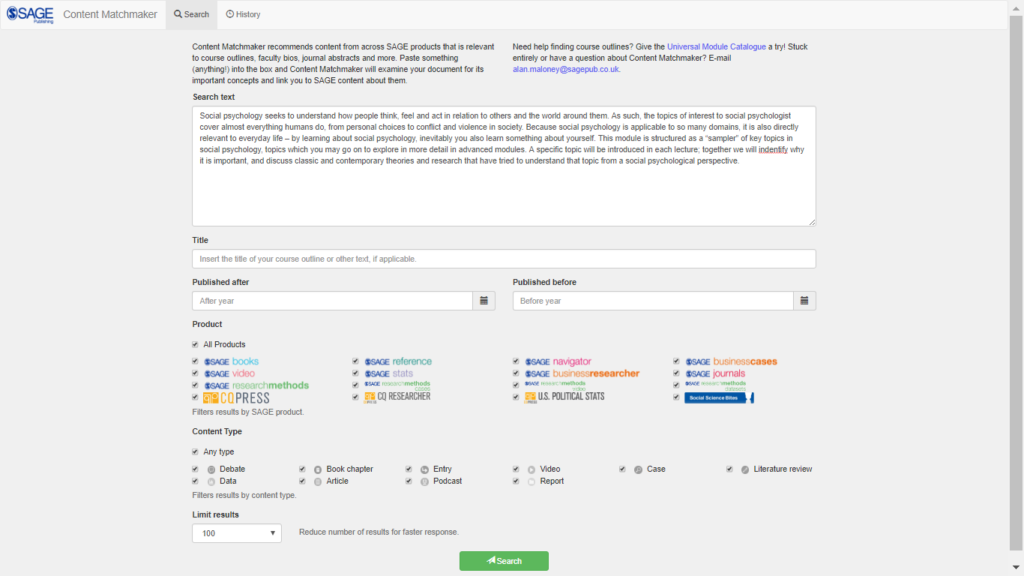
In just six weekly iterations this short project achieved a working prototype with a simple and intuitive interface whereby the user pastes in a piece of text and can optionally limit the search by date published, by content type, or to a subset of SAGE products (see Figure 1).
The tool analyses the text input using NLP techniques and matches keywords identified against the SAGE index to generate a set of results ordered by degree of similarity. The user can drill down the results on screen using a number of facets, or export them as an Excel file or as plain text for further manipulation or to add to presentations or documents. The on screen results contain links that allow the user to look at the content in question and see how that piece of content is related to the input text (i.e. what keywords matched). The tool works with any piece of text including bibliographies, reading lists, abstracts, faculty member profiles.
The interface works well on small as well as large screens, which was important because the sales team typically use tablets when on the road.
The Content Matchmaker has initially been rolled out to a selected user base of sales, marketing and editorial teams.
Business value
Although built as a prototype, the Matchmaker is robust and is being actively used, not only to help the sales team create tailored value reports, but also in the marketing and editorial teams. Users are very impressed by the results they get. They are also discovering a wide range of uses. For example, the open access team are finding potential authors when creating special journal issues by pasting in the abstract of the new special issue. They can then ask previous authors if they would like to write on the subject again.
The use of agile was novel and positive experience for SAGE and they felt they achieved a lot in the 6 week build.
Once the tool has been in use for several months, SAGE plan to gather a round of detailed user feedback and use it to decide what’s next for the tool. Options may include extending it to cover more use cases, rolling it out to more users, and continuing to build out the index.





